



Reliable Order Processing
Processing orders in real-time with KEQ while isolating delays and failures

Written by Henning Rohde and Jordan Hurwitz, members of the engineering teams that work on infrastructure.
At CloudKitchens, real-time food order fulfillment is at the heart of our business. When a customer places an order, an elaborate orchestration workflow is run behind the scenes to ensure the meal is cooked, assembled, and delivered efficiently and seamlessly.
What needs to happen – and when – depends on the specifics of the order and is time-sensitive, typically involving 3rd party integrations with varying characteristics. If an order contains multiple items, each has to be prepared at the right time. If an order is prepared in a facility with conveyance robots, it requires additional coordination. Our internal systems listen to a central order event message bus to understand and react to the state of orders in real time. Lost updates or long delays result in a poor experience for both kitchens and customers.
The nature of order processing presents some unique challenges. To this end, we designed the Keyed Event Queue (KEQ) service as a central message bus for order processing. Today, all orders and order related events flow through the system alongside other internal traffic at CloudKitchens.
Event-driven order processing
Order processing is inherently reactive. Our software systems observe and interact with the physical world, where progress is driven by real-world events, for instance, “customer places an order”, “order ready to pick up”, “driver arrives”, “item removed from locker”, etc. Event-driven systems are commonly structured around an asynchronous, durable message bus, managed by a message broker.
The CloudKitchens order processing system follows this approach:

Orders transition through a dozen or more events as part of fulfillment, some of which are generated internally by our systems or devices. Each consumer service is responsible for a distinct aspect of fulfillment, such as ticket printing or robot conveyance, and reacts to order updates for that purpose. Order progress is driven by events and actions in concert with each other and the physical world. Many thousands of orders are typically in progress simultaneously.
In our kitchens, timeliness and event ordering are important. We originally used Apache Kafka, a widely-used, open-source message broker that offers total event ordering with high performance. Kafka is a standard solution.
However, as order volume grew, our systems started to run afoul of how Kafka works and what it is designed to do well. First, the distinctly heterogeneous order processing frequently involves 3rd party integrations with at times transient failures or delays. Second, our software stack is stretched across multiple regions to overcome regional cloud provider failures. Neither works well with Kafka or similar message brokers.
Head-of-Line (HOL) blocking and failure handling
With Kafka, the order processing message bus is represented as a topic. A topic acts as a queue where emitted events are delivered to each consumer in the same order. Kafka scales its parallel processing by dividing topics into a fixed number of distributed queues called partitions. Each message provides a key that determines its partition. Event ordering is preserved within partitions. With N partitions, up to N consumer instances can process events concurrently.
Although events are processed concurrently across partitions, each partition still contains the events of thousands of different interleaved orders. And because a partition is processed sequentially (with batching), failure to process any event blocks further progress for the whole partition. This situation is known as Head-of-Line (HOL) blocking.
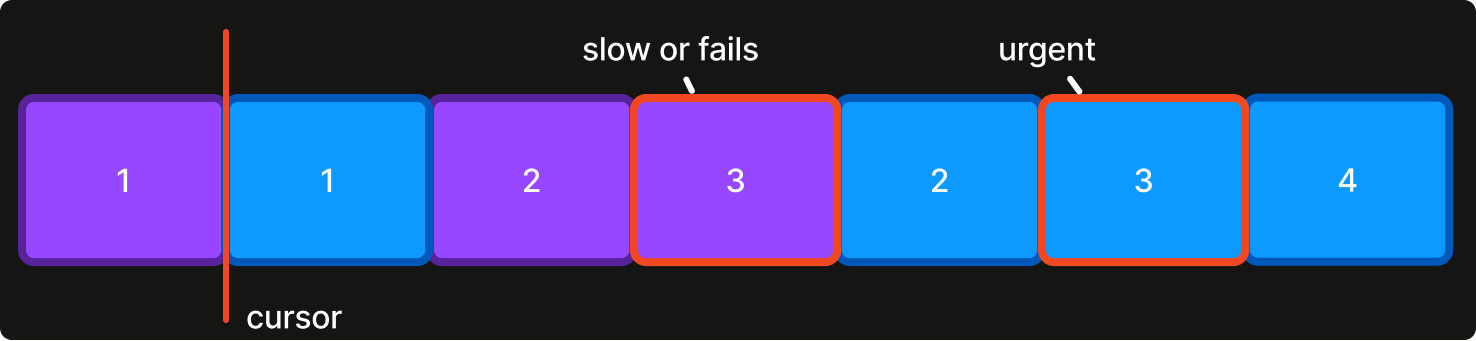
The big question is: if a consumer fails or is slow to process an event, what do we do?
For time-sensitive processing, there are no good simple options. We can wait for event processing to succeed, but that may take a while, during which all later events in the partition are stalled. Or we can ignore the message and move on, which avoids the delay but may fail to act on something important. Either option leads to poor experiences and order cancellations.
To mitigate HOL blocking, consumers must defer failing or slow events one way or another. A common option is to move problematic events to another topic, a so-called Dead-Letter-Queue (DLQ), for later processing. A DLQ ensures progress without losing events.
However, a DLQ introduces other problems: for example, it breaks event ordering when postponed events are processed later than intended. And for transient failures or delays, when exactly should we give up? If we give up too quickly, then even small disruptions create outsized ordering inversions. If too slowly, then processing is still delayed. Such logic is hard to get right when seconds matter. And how do we handle slow or failing DLQ events?
A DLQ works best when it is immediately apparent that an event is “dead” and has no hope of being processed, such as corrupt or invalid data records. This is indeed the case for a large number of Kafka uses. But for order processing it is not quite so simple.
The reality with HOL blocking is that time-sensitive processing involves complicated failure handling. While using a DLQ is a standard solution, it is a solution for another problem. However, since HOL blocking is a consequence of partition mechanics, what if we designed a system to avoid it?
KEQ: A different message broker
Keyed Event Queue (KEQ) is a new message broker based on a deceptively simple idea to avoid HOL blocking: instead of using N permanent partitions, use a separate, temporary partition for every message key. It is the exact ordering we ultimately want for orders: the events of each order are in sequence, but separate orders can progress independently. HOL blocking is then a non-issue, because the scope of each partition is a single order.
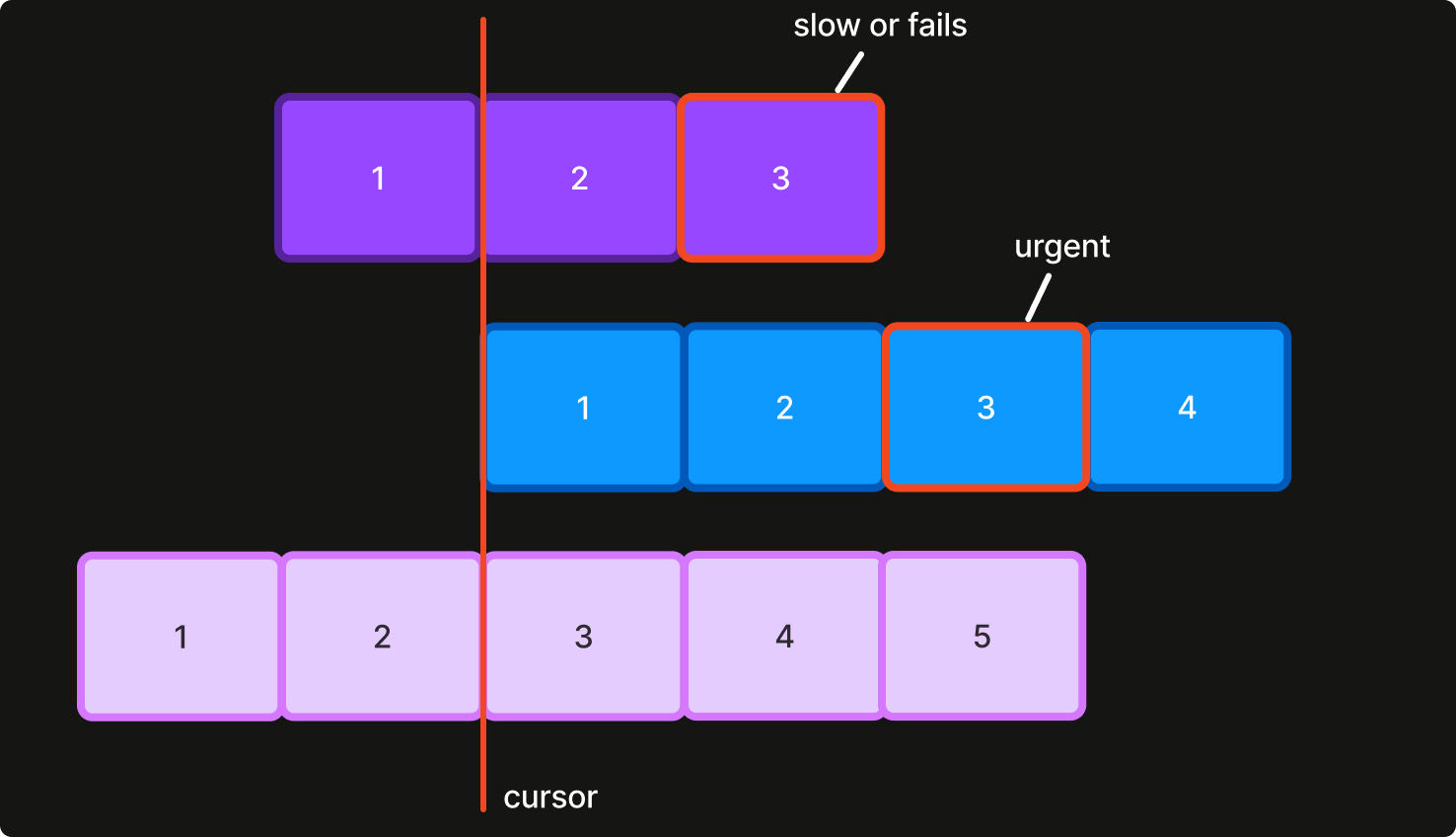
There are additional benefits to this design. Standard techniques for handling transient errors apply, such as retries with exponential backoff. Potentially slow actions can be performed synchronously. Consumer logic – especially failure handling – becomes far simpler. The problems brought by time-sensitive processing and fixed partitions are largely gone.
In addition, there is no N to pick and adjust for the number of partitions as order volume grows. The number of partitions is dynamically determined by the data.
The primary tradeoff with this design is that bookkeeping becomes expensive. Where progress is tracked by a small, fixed number of partition cursors in Kafka for each consumer, KEQ requires millions of such cursors to keep track of the individual progress of each order. Consumers are thereby comparatively heavyweight.
For order processing, neither tradeoff is an issue. Moreover, consumers are almost always caught up and it is desirable that a new event for an order can be sent immediately and processed individually.
Multi-region, low-latency message delivery
KEQ is a multi-region, high-performance and scalable message broker for managing a large number of independent strictly-ordered message queues. It provides an at-least-once ordered delivery guarantee as well as a processing exclusivity guarantee with explicit leases. For consumers, this means that events are delivered in order with no other consumer instances trying to process the same event. This is important when consumer actions involve slow non-idempotent side effects.
KEQ uses an active-active, multi-region distributed SQL database to store messages, cursors, and metadata. That choice makes a tradeoff: it ensures KEQ can honor its guarantees even during a regional cloud provider outage, but I/O latency is necessarily higher than a single-region database.
For performance, KEQ maintains authoritative, sharded in-memory state for each topic using our internal Work Distribution Service. It allows KEQ to track progress and deliver new messages without reading from the database; order and progress updates can be blind writes. New messages are briefly cached and then evicted once all consumers have processed them, usually within seconds.
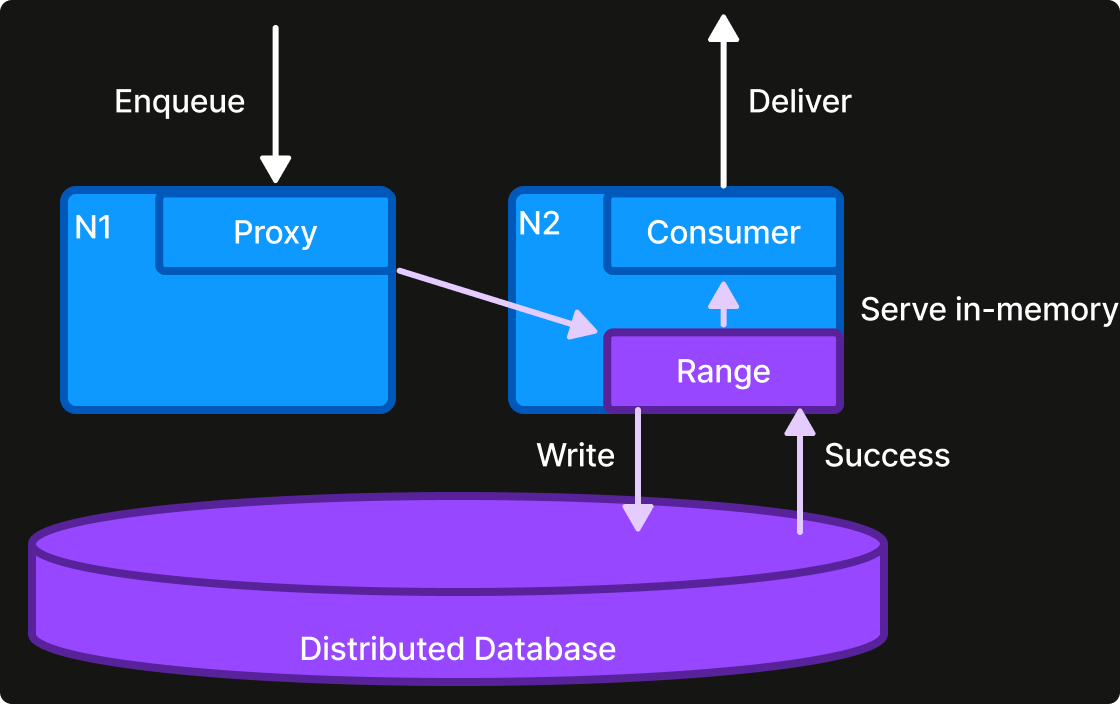
KEQ also optimizes its internal communication, a necessity for low-latency multi-region services. Internally, each topic is divided into key ranges with an explicit region. These key ranges are dynamically assigned by the Work Distribution Service to KEQ instances in their region, so that database operations may benefit from region-locality.
When a consumer instance connects to KEQ, it is internally assigned to specific ranges and a streaming connection is made to each range owner. New and pending messages are thereafter streamed to the consumer, typically from memory and otherwise from the database if it has fallen too far behind.
In addition to topic ranges, KEQ runs an exclusive global leader responsible for allocating and load-balancing ranges between connected consumers. For instance, if two consumer instances are connected, each is assigned half of the ranges while taking into account which ranges are closest to each consumer. This work allocation is dynamic as instances come and go and factors in both region-affinity and node-affinity to minimize delivery latency.
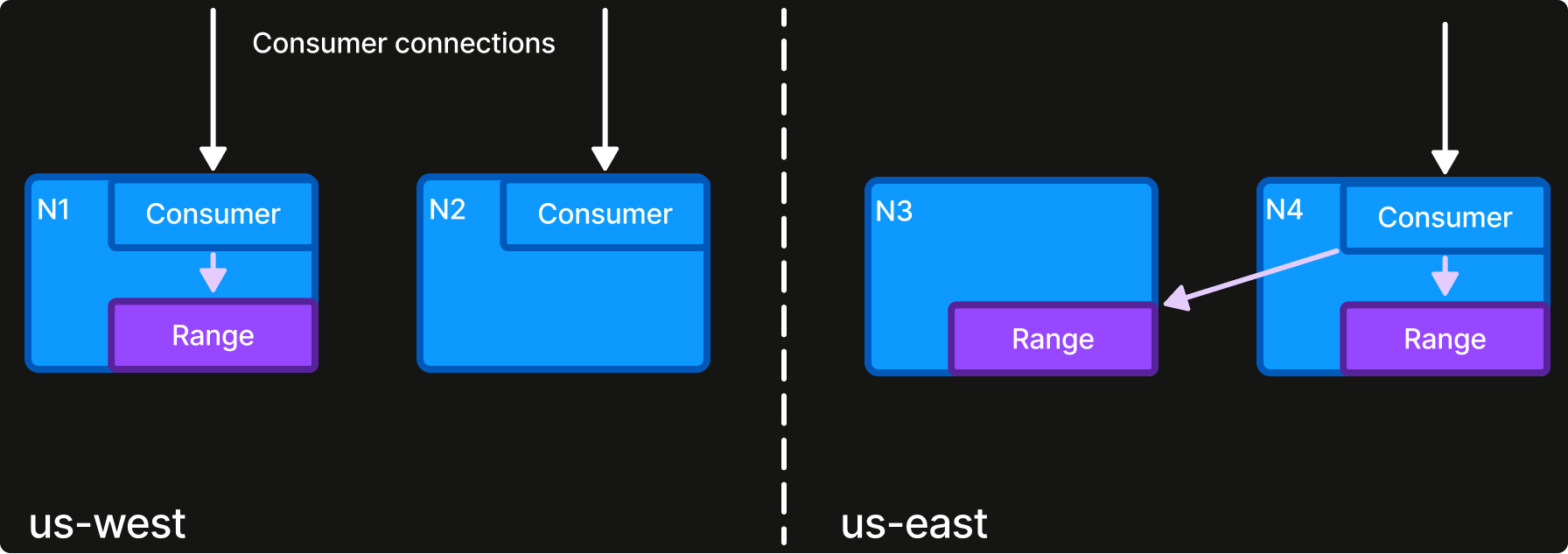
The centralized dynamic allocation simplifies the operational model. Consumer instances are ephemeral and need no individual configuration or coordination; they simply connect to make themselves available. Work is assigned to whatever consumers are present. Wide consumer failures and fast up-scaling are handled equally naturally.
As a result, KEQ works well with auto-scaled multi-region consumers.
Failure-handling revisited
KEQ is built for reliable real-time order processing in adverse conditions. Its active-active multi-region design offers elastic scalability without manual regional failover, explicit re-partitioning or temporary ordering violations. Order event consumers can freely scale up or down to match the rhythm of the restaurant business.
KEQ’s main value is in simplifying how consumers handle failure, transforming failures into delays. With no HOL blocking, consumers can retry transient failures indefinitely without impacting other orders. A DLQ is not needed. Processing failures – and how they are overcome – is handled inline. Even consumer code bugs can be fixed in a reasonable time, which lets consumers sidestep complex failure-handling and detection in favor of a trivial retry.
For widespread system failures, HOL blocking does not matter because no processing will succeed. But consumer code, in practice, never knows which kind of failure is happening, yet it must make a real-time decision. KEQ simplifies that decision. And as Dijkstra put it, "Simplicity is prerequisite for reliability".