



Easy as Pie: Stateful Services at CloudKitchens
How CloudKitchens uses the Work Distribution Service to build real-time, stateful services that horizontally scale.

Written by Jordan Hurwitz and Henning Rohde, members of the engineering teams that work on infrastructure.
At CloudKitchens, our software systems interact with humans in kitchens around the world in real time. From robotic conveyance to reliable messaging infrastructure, these systems need to “just work” to not impede food order fulfillment – yet, at scale, it is traditionally difficult to design and build them well enough to satisfy our latency, correctness and reliability requirements.
There are no simple cookie cutter options. On one hand, stateless designs that rely on databases tend to be too slow. On the other hand, stateful designs that coordinate using Etcd, Redis or internal consensus protocols do achieve low latency, but tend to be too complex and ultimately incorrect or unreliable. Older versions of our systems ran into these conundrums.
To overcome them, we built an opinionated sharding service, Work Distribution Service (WDS), aimed at exclusive in-memory ownership with dynamic explicit assignments, load balancing, and client-controlled routing logic. Today, our most critical, high-performance kitchen systems rely on WDS under the hood.
The Stateless Model
The majority of distributed services are designed to be request-driven – i.e., actions are taken only in response to a request – and stateless – i.e., service instances hold no state beyond the request handling. Persistent state is stored externally, typically in a database, and written and fetched on demand. More requests to the service are directly reflected in more requests to the database.
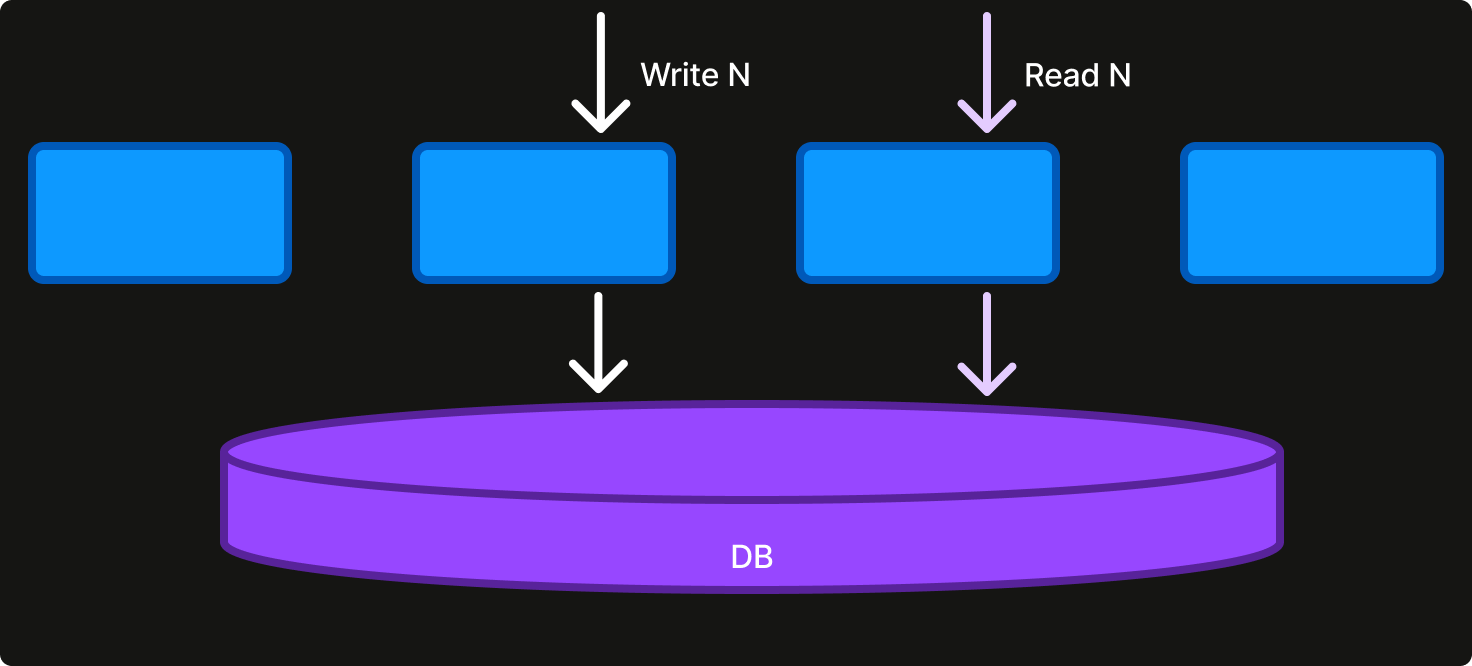
There are a number of perceived advantages to this model:
Scalability. Horizontal scalability can be nominally achieved simply by deploying more instances of the service. However, external dependencies must have their own scalability story and databases often become a bottleneck without careful capacity planning and expertly-crafted database queries and indices.
Simplicity. Service implementation complexity starts lower, since the service limits itself to request handling. However, as requirements on the service increase, they become harder and more expensive to implement, paradoxically ending in an overall more complex system. Low latency and consistency become hard to achieve. How do you rate-limit specific resources? How do you invalidate caches correctly? How do you design performant push-based apis?
Stateless services often end up depending on a battery of external services to overcome these challenges. Caches are used to reduce database round-trips. Timer services provide request triggers. Message queues are used to chain together multiple stateless services. But each dependency adds failure modes, latency, and inevitably introduces its own problems.
The Sharded Model
As an alternative, services can be designed with internal coordination and statefulness instead of necessarily relying on external services. It opens up both powerful opportunities and an abundance of pitfalls. At the heart of its difficulty is horizontal scalability.
The sharded model scales by breaking up ownership of the work domain (e.g. users, orders, stores) into shards and dividing it among service instances. Each shard owner holds exclusive control over certain actions, depending on the use case. For example, a service can use shard ownership to maintain an authoritative in-memory cache backed by the usual database. By making all read and write requests go through the shard owner, it can return cached values from memory with a global read-after-write consistency guarantee – in contrast to the stateless design above.
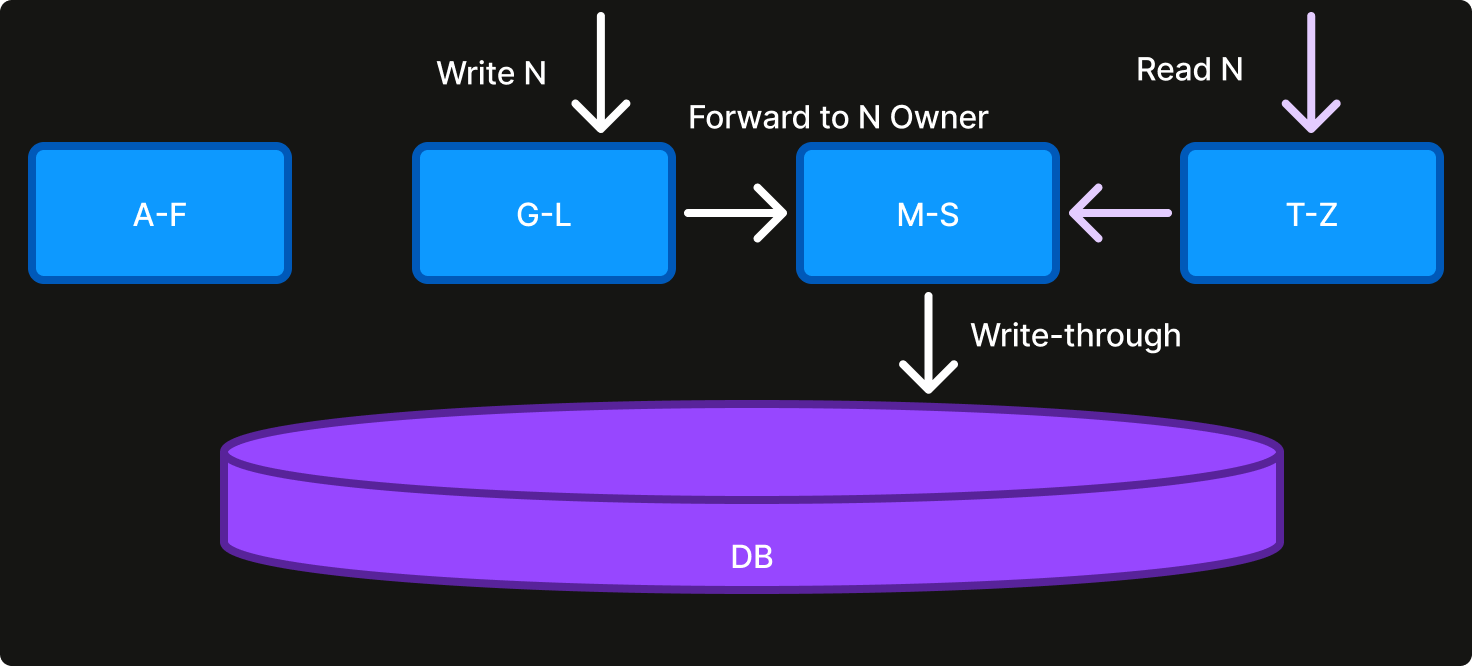
The sharded model provides low-latency and correctness at scale when done well.
But what about reliability and complexity?
This is indeed where one easily runs into trouble. In addition to a partitionable work domain, sharded services implicitly also need:
Ownership. A mechanism for assigning and distributing shard ownership; and
Routing. A mechanism for routing requests to current shard owners.
Two approaches are common: either roll your own internal work distribution mechanism, using a gossip or consensus algorithm or a persistence-based sharding library; or rely on a generalized data store for coordination that implements consensus under the hood like Etcd or Zookeeper. Both approaches require significant commitment and tend to get complex fast. Advanced concerns such as re-sharding, multi-region domains, or graceful handover are often neglected.
Stateless services are widespread for good reasons. At CloudKitchens, we took a different approach.
The WDS Model
The Work Distribution Service (WDS) is a highly-resilient multi-region control-plane service for distributing work to connected clients. WDS makes a number of opinionated tradeoffs aimed at reliability and ergonomics for sharding our real-time kitchen services.
First of all, it targets reality in a modern cloud environment:
Dynamic: service instances are ephemeral. They generally do not use local physical disks and may come and go as the service scales up or down. There should be no special logic needed for auto-scaling nor regional failure. Shards should be load-balanced across whatever instances are connected and shard re-assignments might be mildly disruptive at worst, but fundamentally benign.
Multi-region: services are deployed across multiple regions for geo-resiliency. Shard assignments should align well with underlying databases, where we know or control the data placement for region-local latency. Shard placement decisions should not be the concern of the service and operational controls around data location should be available.
The key needs of the sharded model are handled as follows:
Ownership. Domain and shard management is configured and handled centrally in WDS, which internally uses Raft for distributed storage and coordination. At runtime, service instances establish a connection to WDS to start receiving leased shard assignments. If an instance crashes or loses connectivity for too long, its lease lapses and its shards are assigned to other connected instances.
Routing. Connected instances receive up-to-date shard routing information, i.e., which instance owns what, that can be used for internal forwarding and fanout. This “routing logic as a library” approach is essential: it works for both batch and streaming applications, supports non-1:1 routing and leaves the service in control of the data path.
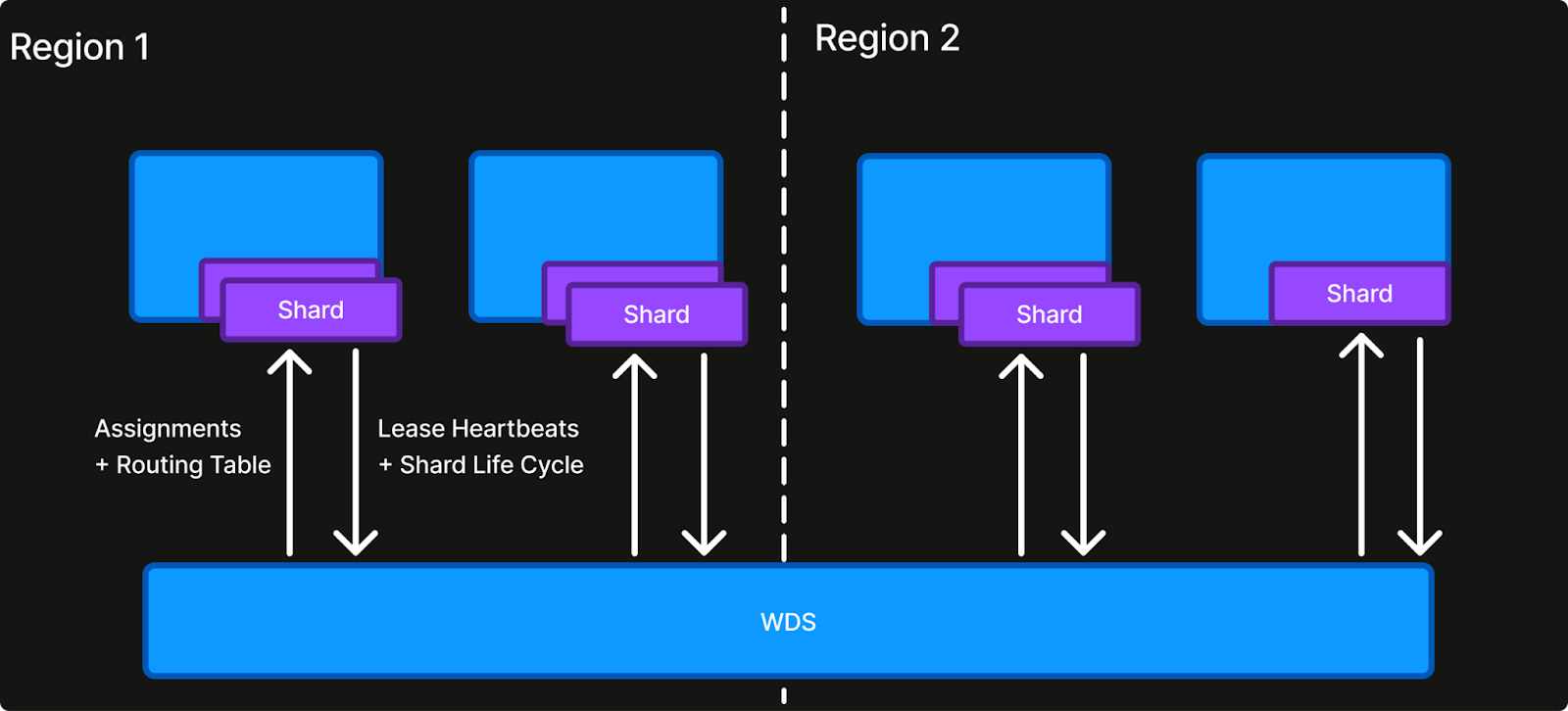
WDS deliberately supports only three kinds of work domains: UNIT (singleton), GLOBAL (UUIDs) and REGIONAL (UUIDs with region). A singleton domain is used for leader election in certain low-scale and advanced use cases. A non-singleton shard is a half-open UUID range for a domain. This seemingly peculiar choice provides a number of advantages over discrete or custom shard spaces (e.g. integers or strings). UUIDs force a uniform distribution that naturally avoids hotspots and shards can be evenly split or merged dynamically. Since services in practice never know their eventual scale upfront as the business evolves, no-downtime re-sharding is a crucial feature. Most entity identifiers are UUIDs as well.
Finally, WDS is also notable for what it does not do. It does not offer storage, instead assuming services use a database for such needs. It does not offer distributed locks, favoring instead “ownership is locking". It does not offer dynamic shard weighting, due to its complex service interaction. Choice is great when it comes to food, but not always for coordination primitives.
Sharding in Practice
In this post, we’ve alluded to Robotic Conveyance Routing (RCR) and Keyed Event Queue (KEQ) as examples of real-time applications that rely on WDS in different ways for internal distributed state and coordination.
For RCR, one of the main challenges is that controlling robots involves high-frequency location sensor telemetry that far exceeds what is practical to persist in a database. RCR uses facility id as a GLOBAL work domain, with each facility handler controlling all robots in it. The facility handler is responsible for both subscribing to telemetry feeds for its related robots and communicating tasks to the connected robots. It is critical that exactly one connection is made per robot to the vendor broker. Robot telemetry largely resides in memory for real-time control, unlike persisted task queues and robot metadata.
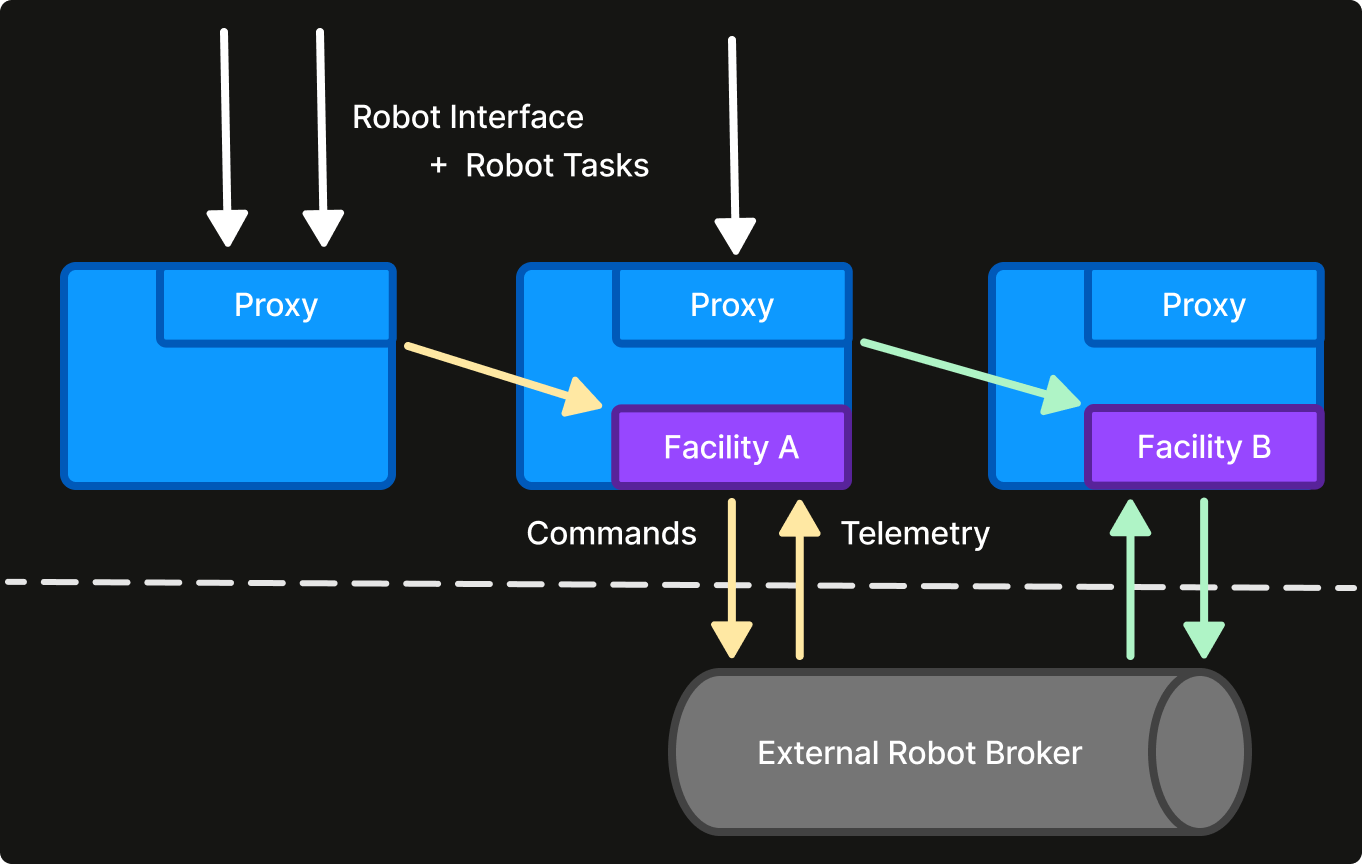
KEQ is a more advanced example. KEQ is a multi-region message broker that stores messages across millions of queues in a multi-region distributed database for resiliency. A key challenge is that such a database incurs high transaction latencies, which is not conducive for real-time message delivery.
For each topic, KEQ uses a WDS domain to maintain consumer progress in-memory and a small authoritative write-through cache for enqueued messages. New messages are briefly cached and then evicted once all consumers have processed them, usually within seconds. In steady state, KEQ does not read messages from the database at all, even as consumers are slightly out of sync with each other. This setup is eminently effective for low-latency message delivery while respecting per-queue ordering requirements.
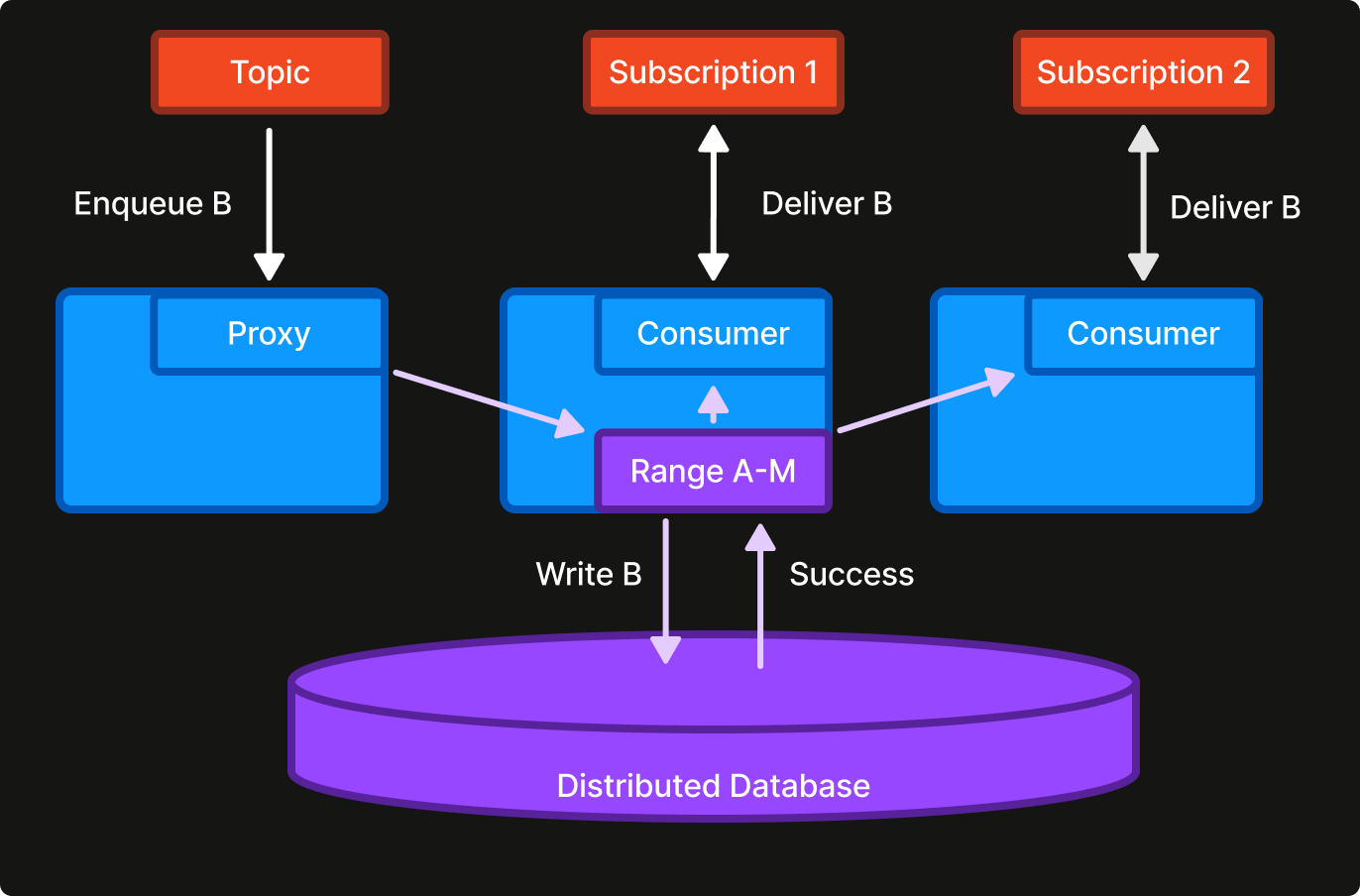
KEQ also uses a UNIT domain to elect a leader for assigning and load-balancing subscribers to specific ranges. The leader uses the WDS routing information to match subscribers with appropriate topic ranges and is an example of non-trivial routing made possible by design.
Conclusion
The Work Distribution Service is an opinionated control-plane service for shard management. Services integrated with WDS can take advantage of powerful built-in primitives for shard ownership and routing to satisfy strict latency, correctness and reliability requirements.
WDS was built to enable real-time scalable kitchen systems that go beyond what the stateless model can achieve. It succeeded. Our most critical, high-performance services rely on WDS as a secret ingredient and are simpler and more reliable for it.