



Nuance: Preventing Schema Migrations From Causing Outages
How CloudKitchens automates the analysis of our database schema migrations.

Written by Alexey Pavlenko and Pasha Yakimovich, members of the engineering teams that work on storage infrastructure.
At CloudKitchens, we reviewed all database-related outages over the last few years and found that roughly 80% were caused by schema management issues. Our analysis revealed several contributing factors:
Wrong assumptions about the current state of the target database. For example, a proposed database schema may not match the one subsequently generated by migration software (e.g. Flyway) via incremental updates. This could happen if the production schema was manually modified ad-hoc at some point (unknown to the same migration software).
Wrong assumptions about how the schema migration is executed. Various database technologies have their own gotcha moments (CockroachDB, for example).
Not knowing nuances of how a particular database implements a schema. As in the previous point, there are plenty of opportunities to make mistakes.
Forgetting the consuming application’s usage patterns. A classic example is deleting a column or index that is still in use.
Let’s walk through a few case studies. All of them were taken from real production outages (simplified for readability). They mostly apply to Postgres and CockroachDB, but are still relevant to other relational database technologies.
Example 1: Broken Uniqueness Constraint
Say we have a table bad_1 defined as follows. What could go wrong?
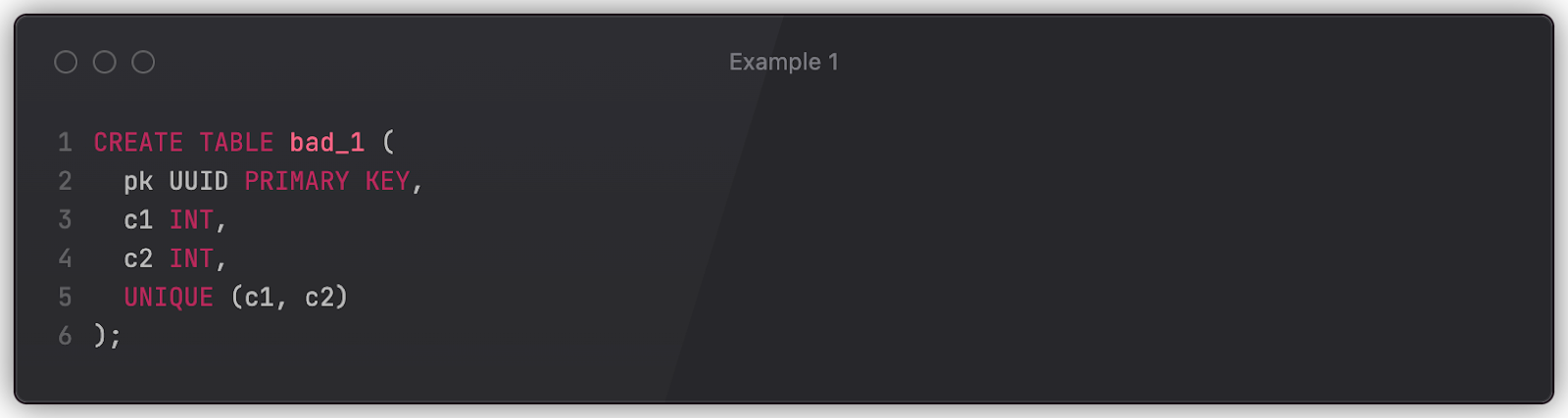
The problem is that the c1 and c2 columns can both be NULL, as they lack a NOT NULL declaration. Consequently, the UNIQUE constraint won’t be enforced on the (c1, c2)pair if either is NULL. It’s worth remembering that NULL in SQL is not a value, but rather the absence of a value. Therefore, comparisons with NULL always produce false, which allows the columns to keep identical values despite the constraint (multiple rows could contain c1=123, c2=NULL). Applications that rely on the constraint must also ensure that no null values are inserted into the table.
This behavior can be altered via NULLS NOT DISTINCT in Postgres, but one has to know about this limitation in advance.
Example 2: Silently Dropping An Index
Let’s examine a schema migration. Say we have a production database defined as follows.

Seeing that column c1 is no longer being used by the application, a developer submits a schema update.

The unexpected consequence of the ALTER statement above is that the c2_c1_index will be dropped as well. After all, two columns are required to populate index entry – without c1, it’s no longer possible. Both CockroachDB and Postgres drop the c2_c1_index silently, which may negatively impact the queries that rely on this index (to quickly filter by c2).
The situation wouldn't be as bad if c2 were dropped instead of c1, because an index is normally associated with the first column in its definition. Therefore, we shouldn’t prevent indices from being dropped if its first column (c2 in this case) is dropped. Well, unless the latter column is in use by the application.
Example 3: Keeping Two Tables In Sync
Here’s an example where the schema definition could result in suboptimal behavior that may only reveal itself under sizable load.
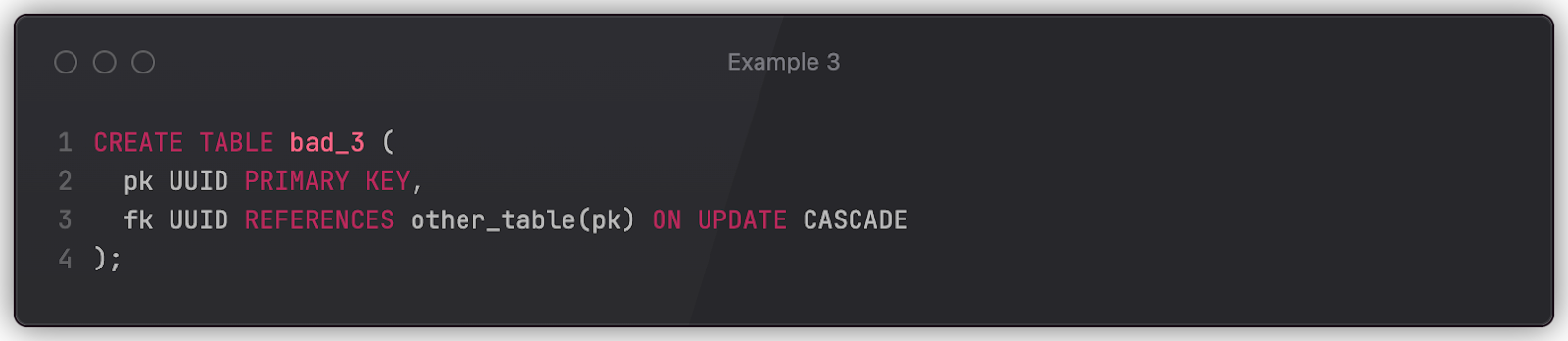
ON UPDATE CASCADE instructs the DBMS (CockroachDB, Postgres) to keep the value of fk in sync with the pk value of the specified table. An update of other_table.pk will automatically change bad_3.fk. We can imagine that the following statement is executed in the same transaction that changes other_table.pk.

This may work fine when our data volume is low or when such requests are infrequent. However, upon a spike of changes in other_table.pk, the DBMS will have to change bad_3 values respectively. And, due to the absence of an index for fk, it will have to run a full scan for every one of them. Which will lead to rapid performance degradation – possibly an outage if the table contains a large number of rows.
Example 4: Potential Runtime Failure
And finally, a simple one.

Is it safe to execute a drop of a table, column, or index? It’s not possible to answer without knowing the context. There can still be references in the application code, or even some 3rd-party system that generates monthly reports. We should use the history of queries to some_table to know with a certain degree of confidence.
Nuance: A Better Schema Analysis System
We should detect the issues discussed above, and more, as part of our everyday development flow. This would maintain developer velocity, ensure that past outages are not repeated, and eliminate the need for manual intervention by infrastructure maintainers. We built Nuance: a schema analysis system to accomplish exactly this!
The idea to analyze and lint schemas is not new. There are a few open-source products that attack this problem. However, they focus primarily on syntax, while we aim to address issues related to the runtime usage of the database. Usability depends on the signal-to-noise ratio – ideally, we want to confidently highlight actual problems rather than focus on indentation and naming conventions. This requires a broader perspective, as the database schema alone is not sufficient to identify problems.
A high-level diagram of the analysis module is presented below.
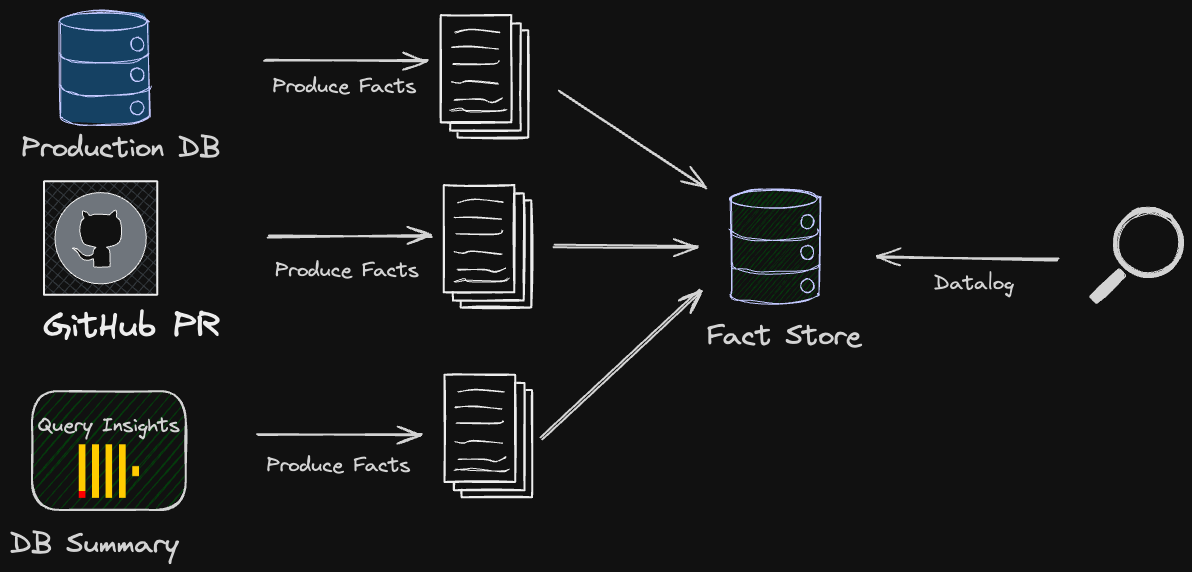
At this point, it’s worth noting multiple data sources that are used to produce facts about both the database schema and the execution environment.
Production Database Schema & Migration Library Metadata
Since any schema upgrade will eventually be applied to a running database, it doesn’t make sense to consider any schema other than the one that is actually deployed to production. It is always possible that the schema committed to the company’s version control system diverges from the actual one, whether due to early experimentation or ad-hoc mitigations. This should be taken into account when assessing whether the upgrade is safe.
For example, Flyway, a commonly used migration tool, keeps the previously applied versions in a special table (flyway_schema_history) assumed to be in sync with the updates committed to a version control system. Nuance can validate this invariant and warn when discovering drift. CockroachDB and Postgres, like most database technologies, easily allow schema dumping, which is then parsed, transformed to AST, and used to derive necessary facts.
Schema Upgrade Statement
These are the actual SQL commands executed against a production database to migrate it to the target schema. Since we store schemas as code, these can be extracted from the developer’s pull request.
Depending on the chosen upgrade path, this can either be a single file with statements, or a list of newly introduced versioned files with incremental updates. Our implementation differentiates these approaches in order to support catching issues where migration tooling depends on whether a change is performed via a single file or multiple.
Database Runtime Information & Query Log
Modern storage technologies expose a lot of information via metrics and system tables. A few examples of the latter are cumulative statistics in Postgres and crdb_internal in CockroachDB.
Additionally, a full log of queries executed against the target database is also extremely powerful. This enables us to assess the ongoing usage of certain entities, whether they be tables or columns. This can also be applied to other use cases, such as access audits and performance monitoring.
We use a system built on top of ClickHouse to store, process, and aggregate both runtime information and the query log of the entire storage fleet. This provides us with a summary of database usage for a given time period. (We also use the same system to monitor and debug performance issues, detect suboptimal transactions, and submit recommendations on resource tuning.)
Other Data Sources
We plan to eventually add more data sources. For example, consider the impact of a schema upgrade on derived systems such as database changefeeds, Kafka topics (plus other message queue technologies), various OLAP consumers, and more. Theoretically, we could fetch this information and use it in the analysis to determine whether there could be a failure further down the pipeline.
It’s clear at this point that a well-designed system allows for the easy integration of new data sources with little to no impact on existing functionality. Such a design requires a certain level of abstraction over the utilized data sources. More on that below.
Datalog and Fact Store
Instead of delivering data in an aggregated state specific to the source (e.g., a full database schema snapshot as SQL or AST), we can split it into individual facts (e.g., table X has column Y, column Y is of type INT, column Y is NULL-able, index IDX was used N days ago, etc.). This becomes a "database" of facts that can be queried uniformly.
With a database of facts, the next step is to implement rules that extract interesting properties from it (problems or recommendations) – optionally unwinding multi-level relationships between individual facts.
This approach is a natural fit for logical languages, particularly Prolog and Datalog. We use the latter and rely on the Datalog implementation by Google Mangle project.
During validation, information extracted from the data sources above is converted into facts (atoms) that are stored in an in-memory fact store. Individual rules query this to check for the existence of interesting properties. Successful rule evaluations, depending on the purpose of the rule, indicate either a potential issue or an optimization opportunity. All atoms in the store are unique; therefore, by using atom terms (arguments), it’s possible to point to the specific change and improve developer awareness.
Putting It All Together
Let’s see how it’s done in practice. Below is a Datalog source code of a rule that checks that no nullable column is a part of the UNIQUE constraint (Example 1). In our codebase it’s associated with a Code that uniquely identifies the rule itself, warn-level Severity (not good, but not necessarily outage-inducing), Unit to define the top-level rule and accompanying sub-rules (presented below), and the Predicate to indicate the name of the top-level rule (uniq0001).
The analysis engine will evaluate the top-level rule, and if it produces results, then there’s indeed an issue. We can generate its human-readable description by using the accompanying template that receives terms (arguments) of result atoms that uniq0001 produces. This description will point to the exact entity that has a problem (Table and Column).
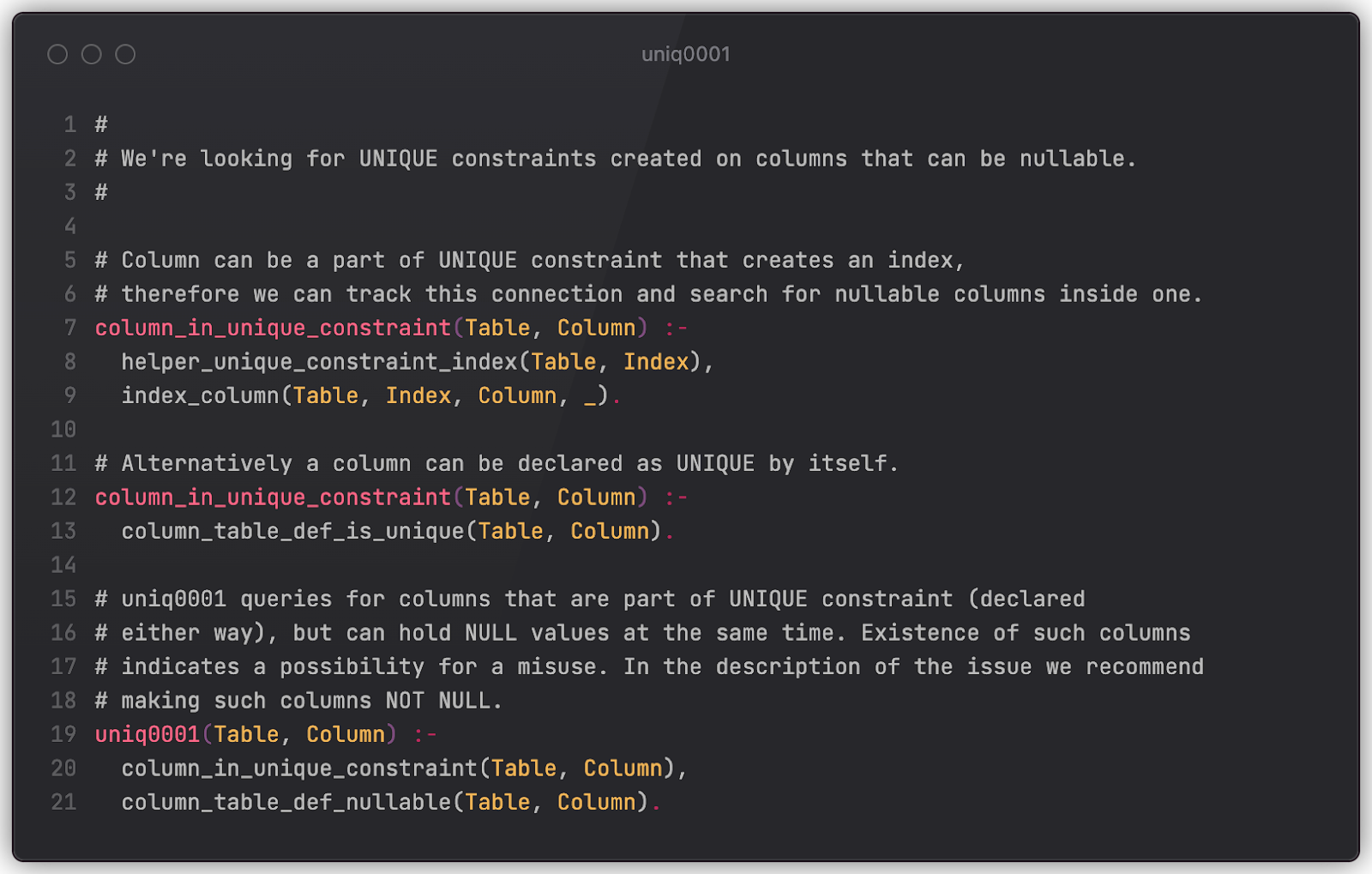
Let’s try to solve Example 2. The rule below checks for situations when an ALTER TABLE DROP COLUMN statement tries to drop a column that is secondary to some index. “Secondary” here means that the column is either not the first one in the declaration list or is a column that’s only stored in an index for faster retrieval (e.g. a covering index for index-only scans).
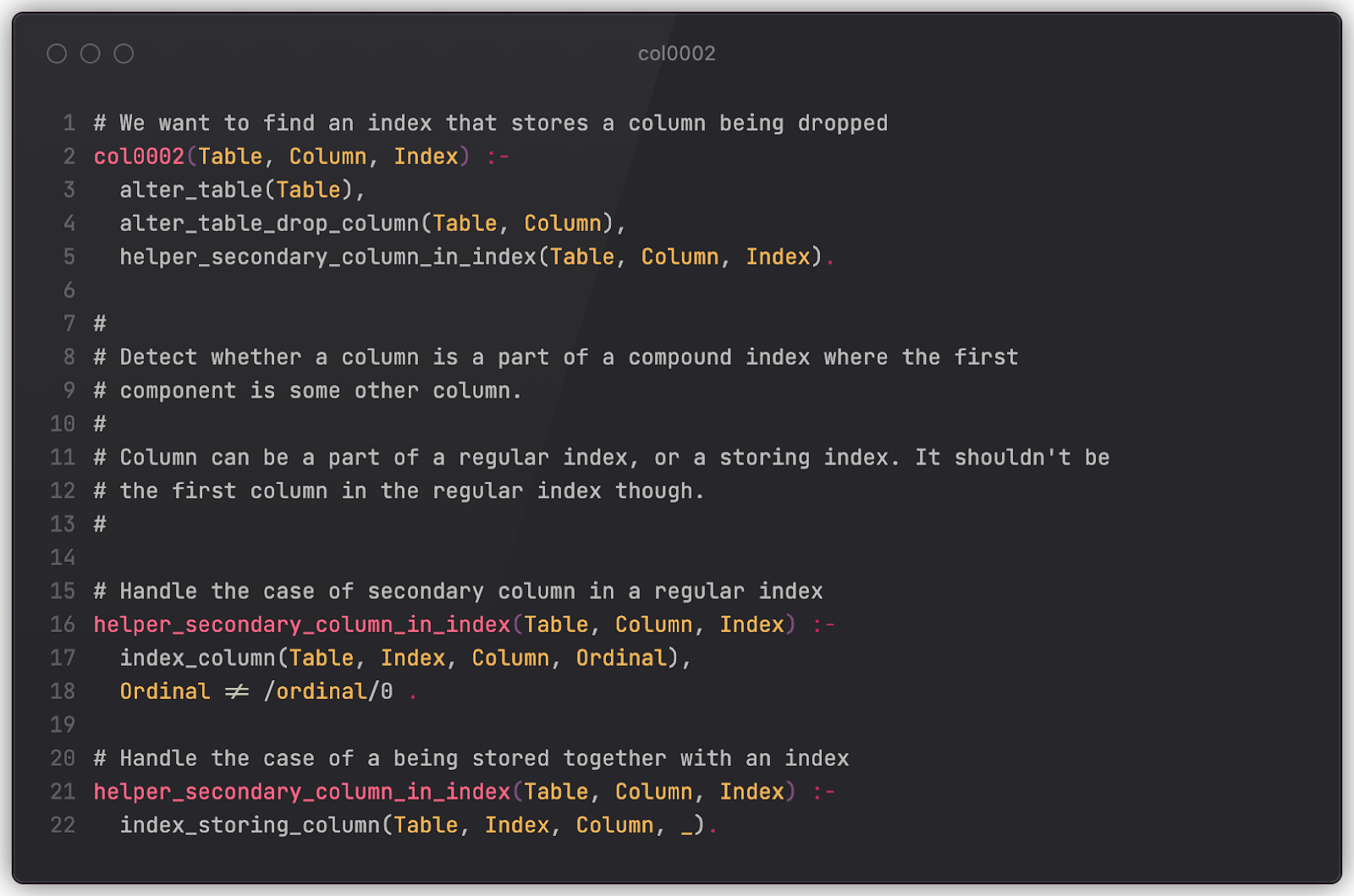
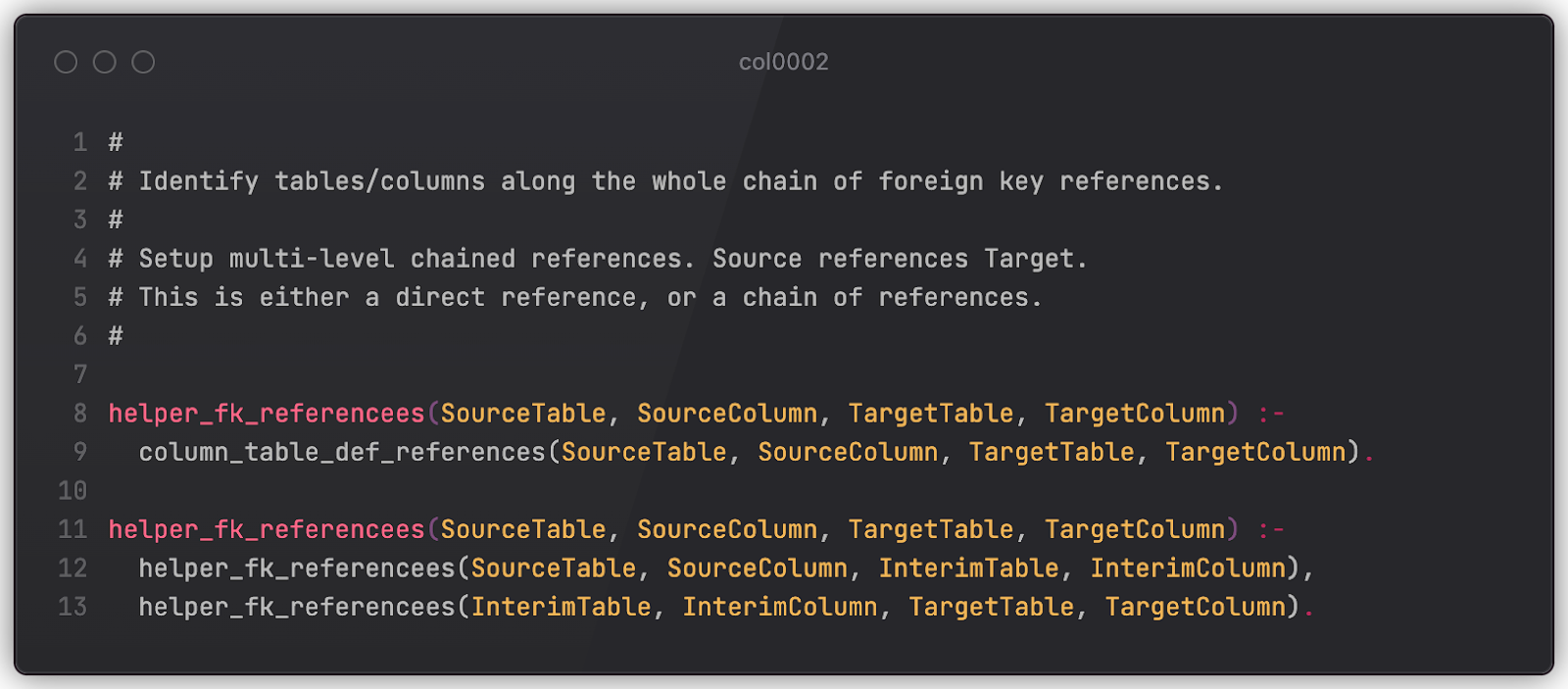
To make things more complicated, imagine a chain of tables that point to one another via foreign keys (official reference). A CASCADE drop of the first column in a chain may trigger respective drops in all linked tables, which at some point may lead to exactly the same issue (unwanted index drop). A more sophisticated rule (only a part of it is presented here for brevity) may check for that as well. (This is also applicable to Example 3.)
Finally, having table / column / index usage information from recent queries (transformed into respective facts) enables us to trivially solve Example 4. All we need to do is check whether the table has been accessed within the last N days (where N is sufficiently large).
As we can see, Datalog is pretty expressive. It has become evident during the implementation that any generic approach based on more common programming languages (e.g., Golang) would need to implement some portion of the Datalog engine anyway – so we’re happy with our choice!
Developer Experience
Nuance appears to developers as just another lint check triggered by a new or updated pull request. If there are no issues, the pull request can be merged as usual. Otherwise, we block it and present resolution opportunities.
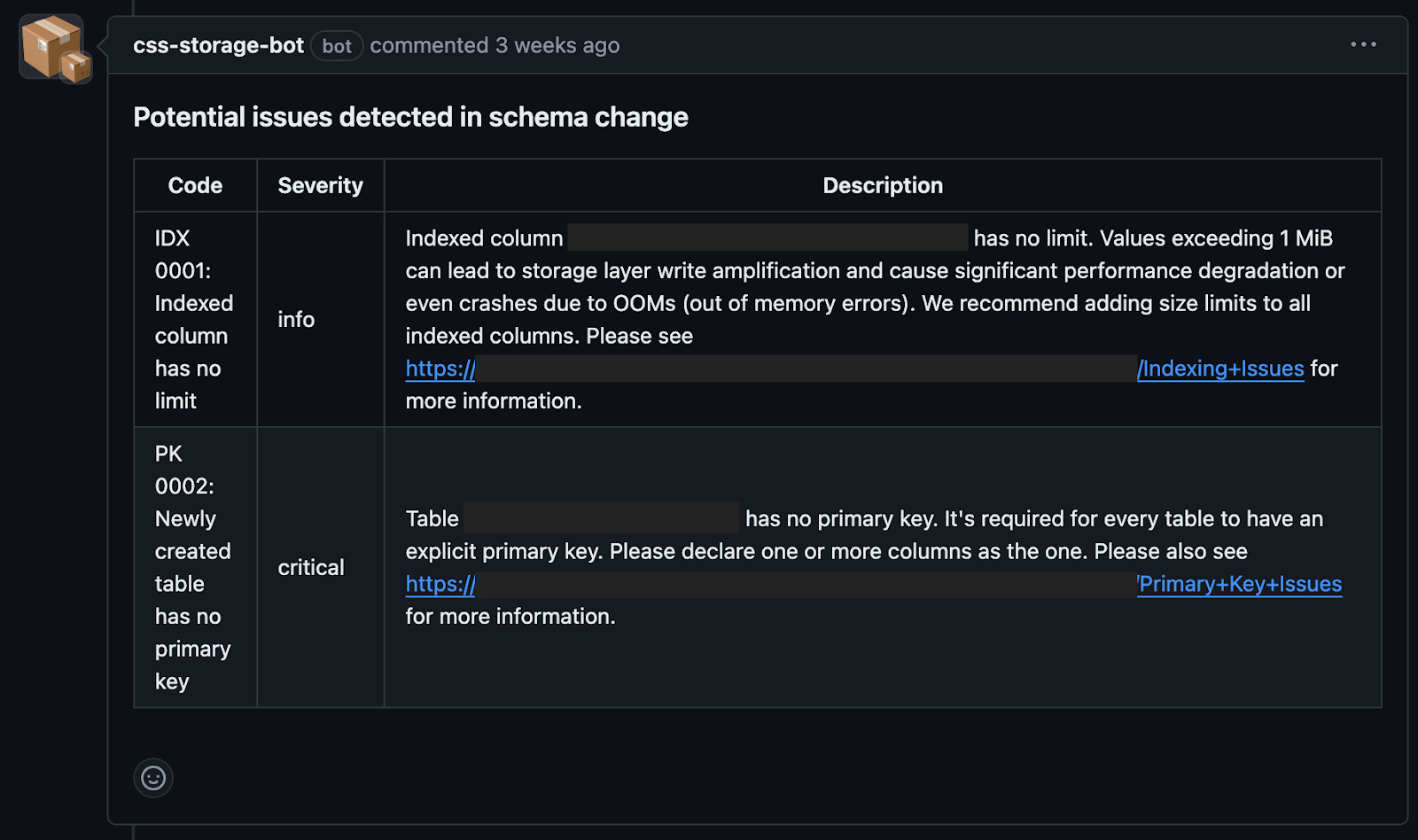
Not all detected issues require immediate action. Sometimes, users are confident in their changes, or the detected issues are merely informative. To accommodate these scenarios, we left an escape hatch enabling users to acknowledge and skip the detected issues.
Command Line Tooling
We’ve augmented Nuance with two important CLI commands.
The validate command enables developers to submit their SQL scripts for analysis and issue detection. Behind the scenes, this command spins up the same validation process that runs for pull requests. This includes fetching the production or staging schema and retrieving real-time query data, ensuring a comprehensive analysis.
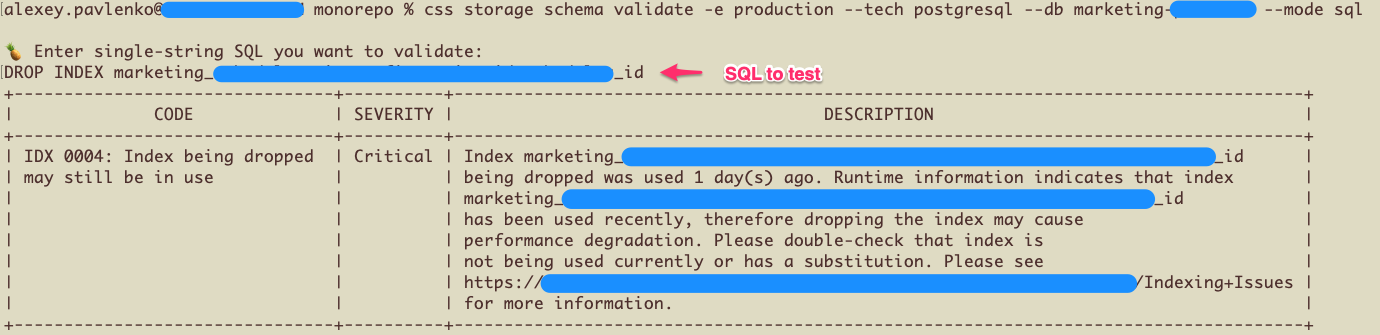
The inspect command inspects the live database schema for any existing issues.

Both CLI commands make it easy to experiment, analyze, and detect issues before developers even submit pull requests.
Documentation
When presenting an issue, along with a brief description, we always include a link to more detailed documentation. The issue page typically contains a longer description, examples, extracts from official documentation, code snippets, and links to past outages and their associated postmortems. This is critical for the smooth adoption of Nuance. By educating developers and improving their awareness, we teach them to trust the tool, preventing it from being viewed as a noisy distraction.
Results
At CloudKitchens, Nuance has been running in production for almost a year. In its current state, it has accommodated past outage history and checks for common anti-patterns and flaws described in Postgres (e.g., here) and CockroachDB documentation.
Current statistics show that 56% of our pull requests with schema changes initially contain issues, 23% of which are critical (guaranteed to cause outages, either immediately or later on). When developers become aware of the issues through tooling, we no longer see outages repeat themselves. As our infrastructure evolves, we will continuously improve and augment our ruleset.