



ML Infrastructure Doesn’t Have To Suck
Our journey to build a simple but effective user-centric ML stack

Written by Karthik Manamcheri and Alex Filipchik, who lead the data and the infrastructure teams.
Introduction
In a perfect world ML infrastructure would work like a well-oiled machine, balancing competing needs for flexibility, usability, maintainability, and cost effectiveness. Time from idea to production would be mere minutes. Let's be honest: many companies, including ours, often fall short. Users face a jigsaw puzzle of systems cobbled together with digital duct tape. "Synergy" isn’t exactly the word that came to mind.
Over the last year, we’ve begun fixating on productivity of Data Scientists foremost. We swapped out some conventional tools and patterns. Data Science teams estimate iteration speed has already increased several fold with our initial results.
Lessons from Our First Attempt
Our initial ML infrastructure was ambitious but flawed. We aimed to build an industry-leading and future-proof system which supports undefined use cases and avoids vendor lock-in. This led us to a tech stack that included
Kubernetes and Istio for the compute and service mesh
Trino and Apache Hudi as the data warehouse layer
Argo and a modified kubeflow pipelines SDK for workload orchestration
MLFlow, Jupyter Notebooks, and Seldon for rapid model iteration
and Bazel as our build system
While this setup offered flexibility and extensibility, it was overly complicated. Data scientists faced steep learning curves with containers, Helm, and YAML. Simple ML tasks took over 10 minutes to start, and setup times for more complex tasks could exceed 45 minutes. Bazel, though powerful for languages like Java and Go, was cumbersome for Python due to compatibility issues.
Through this experience, we learned several key lessons:
Complexity Hinders Productivity: Even powerful tools can become a liability if they're too complicated.
User Experience is Crucial: Prioritizing usability is essential to ensure efficiency and ease of use.
Flexibility vs. Functionality: It’s important to balance flexibility with the need for a simpler, more maintainable system.
Realizing these complexities were holding us back, we knew it was time for a change. In the next section, we’ll explore our new, user-focused ML infrastructure. This redesigned stack eliminates the pain points of the past while maintaining the scalability and ensuring we are prepared for future needs.
The New ML Infrastructure
Internally, we call our stack the ✨DREAM✨ stack!
Daft
Ray
poEtry
Argo
Metaflow
Our new ML Infrastructure can be viewed in roughly 3 layers: Infrastructure, Services, and Libraries. Here is a diagram of each layer and corresponding tech stack:
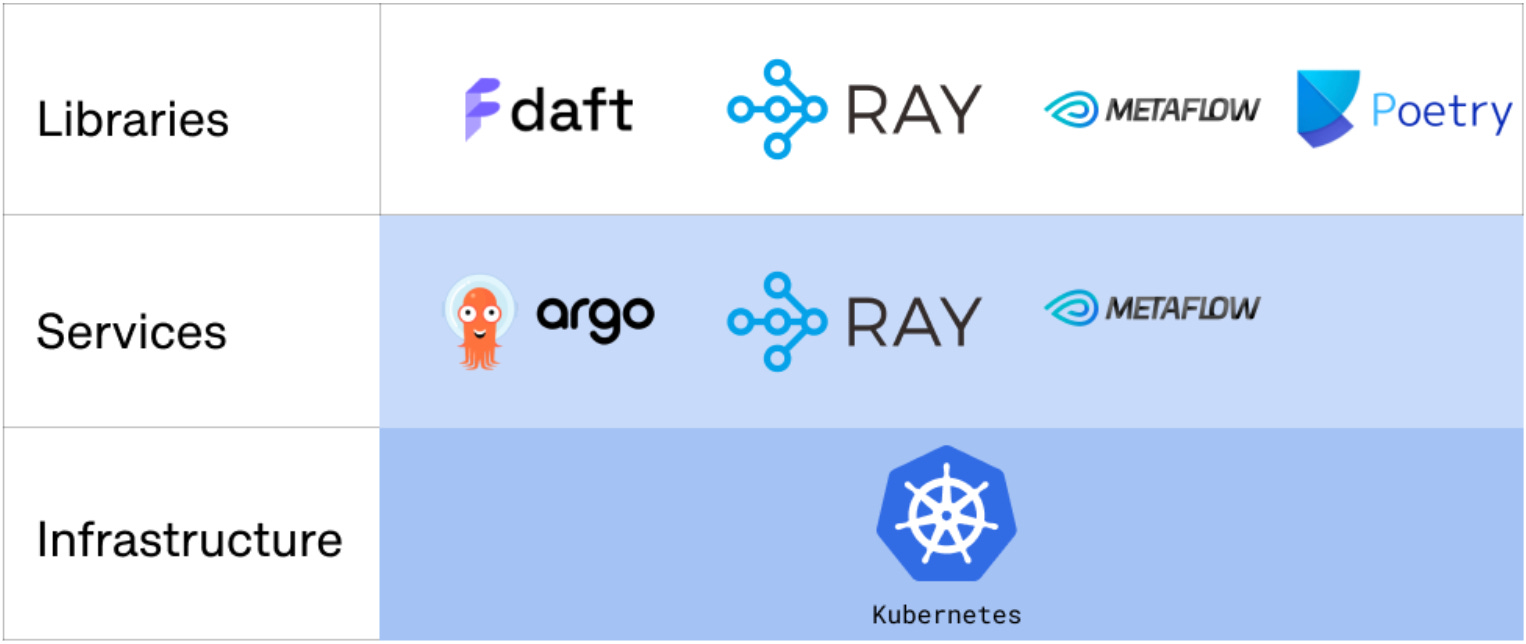
Kubernetes: As we mentioned, we are a big Kubernetes kitchen (look at our cool Kubernetes related blog posts here, here, and here) and we run all our applications and services on it. Our old and new ML Infrastructure run on Kubernetes, so there are no changes there.
Argo: Our trusted workflow orchestrator over the past five years. However, it does come with some challenges. First, it’s quite low-level, often diving into infrastructure details that users would rather not deal with. The primary interface is YAML, which can become complex quickly, even with language wrappers. Another challenge is that developing and testing locally is significantly different from running it in a cluster. Local development requires custom CRDs and ongoing maintenance, making the process a bit complicated. To address these issues, we introduced Metaflow, which tackles these specific challenges and simplifies the workflow by keeping Argo behind the scenes.
Metaflow: This is a user-centric framework that helps data scientists and engineers build, manage, and deploy data workflows at scale.. Metaflow lets you write and debug workflows locally, then scale them effortlessly to production with Argo (or others) when you're ready to go big. It delivers the 'infinite laptop' experience by integrating smoothly with Argo and Kubernetes, giving you the power of the cloud without the headache of YAML. And since it’s all in Python, our users can finally leave the YAML struggles behind and focus on what they do best—creating impactful ML projects.
Ray: Ray is a distributed compute engine for data and AI workloads. Ray serves up a high-performance cluster with a side of Python libraries, making it a breeze to interact with. It’s got a menu of ready-to-use libraries for ML tasks like Ray Data for preprocessing, Ray Train for training, and Ray Serve for serving.
Ray is positioned primarily as a compute engine for AI/ML tasks. Given its architecture, we believe it can also excel in data processing, potentially disrupting well-established frameworks like Spark and Flink. That's why we are doubling down on Ray as our main data compute framework. However, one issue with the Ray library for data processing, Ray Data, is that it doesn't cover the full range of DataFrame/ETL functions and its performance could be improved. That's where Daft is here to save the day–
Daft: Our latest and greatest kitchen gadget for ETL, analytics, and AI/ML at scale. It fills the gap of Ray Data by providing amazing DataFrame APIs that cover our needs. In our tests, it’s faster than Spark and uses fewer resources. Plus, its seamless integration with Ray has made it our go-to for whipping up scalable, high-performance data workloads. Our users are loving its APIs and experience. It makes working with big datasets a breeze. And since it’s written in Rust, it’s practically a tech Twitter darling by default 😛
Poetry: Given the challenges of mixing Bazel and Python—an oil-and-water scenario—we sought a more suitable alternative and landed on Poetry. This well-established tool proved to be both pluggable and extensible, perfectly aligning with our needs. Its ability to support multiple library versions has been a game-changer, accommodating Python’s diverse and ever-evolving ecosystem. The adoption of Poetry has significantly improved the efficiency of our Python developers, reducing dependency conflicts and simplifying library updates. While Bazel remains our tool of choice for other languages, Poetry has streamlined our Python workflows, making development smoother and more productive.
In the next section, we’ll showcase how we used the new ML stack using a case study
Case Study: Calculating high-demand zones
At CloudKitchens, we’re all about turning chaos into culinary gold— and that starts with data. Let us tackle a deceptively simple task: calculating high-demand zones for food orders. Why? Because it is very useful to know where people are hungry before building out a new kitchen facility.
The Challenge: Find Hungry Zones Before Dropping $$$ on Real Estate
This would have taken us a week (or more) to build on our previous stack. It would be amazing if we could do this in a single day. Below we’ll show how, with our new stack. As with every problem, data is the first step…
Step 0: Scaffolding the Dream (aka Hello, World! 👋)
Every epic begins with a humble start. Ours starts with a folder.
mkdir my_project1
cd my_project1
poetry init🎉 Voilà! A Python project is born. If you’re new to Poetry, the pyproject.toml file is like the ingredient list for our project. Here’s a quick look:
[tool.poetry]
name = "my-project1"
version = "0.1.0"
description = ""
authors = ["my.name <my.name@cloudkitchens.com>"]
readme = "README.md"
[tool.poetry.dependencies]
python = "^3.12"
css-metaflow = "*"
h3 = "*"
css-dw = "*"
...It’s basic for now, but we’re about to turn this into a Michelin-starred script.
Step 1: Defining the Flow (the recipe 👨🍳)
We need to break down the task into manageable bites. Enter Metaflow—our trusty sous-chef for data workflows. Here’s what our recipe looks like:
Start: Logs that something’s happening.
Read: Get the order data.
Calculate: Identify high-demand zones.
Write: Save results for future feasting.
End: Logs that we’re done.
Here’s the skeleton of our flow:
from metaflow import FlowSpec, step, poetry
@poetry
class MyFlow(FlowSpec):
@step
def start(self):
print("Starting the flow!")
self.next(self.read)
@step
def read(self):
# Fetch data
self.next(self.calculate)
@step
def calculate(self):
# Calculate high-demand zones
self.next(self.write)
@step
def write(self):
# Save results
self.next(self.end)
@step
def end(self):
print("Flow complete!")
if __name__ == "__main__":
MyFlow()This file is a straightforward Python script with a few well-defined functions, but there are three key elements worth noting:
Inheriting
FlowSpec: This step transforms the class into a Metaflow class, enabling it to function as part of a Metaflow workflow.Decorating functions with
@step: Each function marked with @step becomes a distinct step in the workflow, orchestrated by Metaflow.Decorating the class with
@poetry: This is our in-house Metaflow plugin decorator. It reads thepyproject.tomlfile and ensures that all specified dependencies are seamlessly integrated and available within the Metaflow environment.
Step 2: Implementing the Flow (the cooking 🍳)
Here’s where the magic happens:
Read: Pulls data on fulfilled orders
Calculate: Groups orders by geographical H3 hexes.
Write: Saves the results to our data warehouse.
Here’s the same flow in previous step, but with implementation:
import logging
from metaflow import FlowSpec, poetry, step, project
import css_dw as dw
import h3
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@poetry
class MyFlow(FlowSpec):
"""Calculates high-demand zones."""
@step
def start(self) -> None:
"""Start the flow."""
logger.info("MyFlow run started!")
self.next(self.read)
@step
def read(self) -> None:
"""Reads order data from the data warehouse."""
self.read_table_result = dw.read_sql_as_table(
sql="""
SELECT order_id, latitude, longitude,
subtotal, order_time
FROM fulfilled_orders
WHERE city='San Francisco, CA' AND
order_time >= '2024-01-01'
""",
)
self.next(self.calculate_high_demand_zones)
@step
def calculate_high_demand_zones(self) -> None:
"""Calculates high-demand zones."""
df = dw.read_sql_as_df(
schema=self.read_table_result.schema_name,
table=self.read_table_result.table_name,
df_type="daft",
)
h3_resolution = 8
df = df.with_column(
"h3_area",
df["latitude"].zip(df["longitude"]).map(
lambda ll: h3.geo_to_h3(ll[0], ll[1], h3_resolution)
)
)
self.summary_df = df.group_by("H3 Area")
.agg({"subtotal": "sum"})
.rename({"subtotal_sum": "Total Orders"})
self.next(self.write)
@step
def write(self) -> None:
"""Writes high-demand zones to the data warehouse."""
self.result = dw.write_df_as_table(
df=self.summary_df,
mode="overwrite",
)
logger.info("Output written to DW.")
self.next(self.end)
@step
def end(self) -> None: # pylint: disable=no-self-use
"""End the flow."""
logger.info("MyFlow is ending")
if __name__ == "__main__":
MyFlow()The result? A table of hexagonal zones with order counts. Think of it as a heatmap for hangry customers.
Step 3: Scaling Up (Because 200 Million Rows Is a Lot)
If you’re working with millions of orders, your laptop might throw in the towel. Enter Ray, our scalability hero. With just one decorator, we turn the “calculate” step into a parallelized powerhouse:
@step
@raystep
def calculate_high_demand_zones(self) -> None:
...That’s it. Ray handles the heavy lifting, so you can focus on the fun stuff.
The @raystep decorator is an in-house Metaflow extension, much like @poetry. It seamlessly integrates Ray into your workflow by submitting the code package to a Ray cluster for execution. This allows your tasks to scale effortlessly across multiple nodes without requiring any changes to your underlying code.
Step 4: Automating the Flow (Because Daily Data Is Best Data)
Want this flow to run daily? No problem. Add a schedule decorator:
@schedule(daily=True)
@poetry
class MyFlow(FlowSpec):
...Then deploy it with Argo Workflows:
poetry run python my_project/flow1.py argo-workflows createResult: The DREAM Stack in Action
By combining the best tools, we created a scalable, maintainable, and automated system for identifying high-demand zones. This helps the business make decisions such as buying real-estate for future cloud kitchens a breeze! In addition to this, we are also on the cutting edge of data processing tools here. The tools we have picked are less than 5 years old, and are being actively developed,
Wrapping it all up
In our journey to revamp our ML infrastructure, we've learned a lot about balancing flexibility, usability, and performance. The result? A highly efficient and user-friendly environment for our data scientists and engineers.
Our new setup, the DREAM stack, includes:
Daft: For data manipulation and calculations
Ray: For scalability
Poetry: For dependency management
Argo: For workflow automation
Metaflow: For a superior developer experience
Together, they make data engineering simple, effective and easy-to-use.
The impact has been immediate: our new data scientists can now spin up projects in a matter of hours, a process that previously took weeks. This increased productivity is a testament to the effectiveness of the DREAM stack.
Thank you for joining us on this journey. We hope our insights and experiences help you in building an effective ML infrastructure that doesn't suck. We’re going to keep pushing and making this even better. If you’re passionate about working on this, message me on LinkedIn or look at our positions. We are always looking for people to help us push the boundaries.